In recente onderzoeken voor het Wetenschappelijk Bureau NSC is gekeken naar het Fries, Nedersaksisch en Limburgs. Daarbij werd één ontwikkeling steeds zichtbaarder: minderheidstalenbeleid verschuift van juridische erkenning naar digitale infrastructuur. De vraag is niet langer alleen welke rechten op papier bestaan, maar hoe talen functioneren in digitale dienstverlening, in vertaalmachines en in algoritmische systemen.
Minderheidstalen in het Europese raamwerk
Voor een helder gesprek over minderheidstalen helpt het om het onderscheid scherp te houden tussen recente migrantentalen en historische, territoriaal verankerde minderheidstalen. Het Europese kader dat Nederland de afgelopen dertig jaar volgt, het Europees Handvest voor regionale talen of talen van minderheden van de Raad van Europa, sluit talen van migranten expliciet uit. Het richt zich op talen die traditioneel binnen een staat worden gebruikt door staatsburgers die numeriek in de minderheid zijn en die verschillen van de dominante officiële, nationale taal.
Het Europese taalminderhedenbeleid draait in Nederland vooral om het Handvest van de Raad van Europa. Dit Handvest kent twee beschermingsniveaus. Deel II (met name artikel 7) legt algemene doelen en beginselen vast—zoals respect, bevordering en facilitering van de taal. Deel III vertaalt die vrijblijvende doelen naar concrete verplichtingen in domeinen als onderwijs, bestuur, media en cultuur. Landen kiezen daarbij uit een “menu” van opties en committeren zich vervolgens aan de uitvoering daarvan.
Voor Nederland is de tijdlijn helder: ratificatie in 1996 en inwerkingtreding in 1998. In Europees Nederland zijn onder Deel II onder meer Limburgs, Nedersaksisch, Jiddisch en Romanes erkend; het Fries is in Fryslân aangewezen onder zowel Deel II als Deel III. Sinds 2024 is bovendien Papiaments in Europees Nederland erkend onder Deel II; op Bonaire geldt Papiaments onder Deel III.
De kernvraag is vervolgens niet alleen “wat staat er in verdragen?”, maar “wat volgt daaruit in de praktijk?”. De Raad van Europa monitort de uitvoering via periodieke evaluaties en aanbevelingen. In recente rapportages over Nederland wordt expliciet gevraagd om het gebruik van het Fries, Limburgs en Nedersaksisch te versterken. Digitalisering duikt steeds vaker op als een knelpunt. Veel minderheidstalen zijn digitaal sterk ondervertegenwoordigd, vooral in officiële structuren. Rechten bestaan pas echt als ze in werkprocessen, platforms en dienstverlening zijn ingebouwd.
Fries: van Kneppelfreed naar bestuurlijke routine
Als er één moment is dat vaak terugkeert als omslagpunt in de Friese taalstrijd, dan is het Kneppelfreed van 1951: een confrontatie rond het gebruik van het Fries in de rechtszaal die landelijk de aandacht trok, politiek werd ingezet en leidde tot meer rechten voor het Fries. Deze gebeurtenis blijft relevant omdat het laat zien dat taalrechten niet primair ontstaan uit liefde voor erfgoed, maar uit botsingen over toegang tot instituties.
Die institutionele lijn loopt door tot de Wet gebruik Friese taal (2014), die expliciet gelijkwaardige rechten geeft aan het Nederlands en het Fries als officiële talen van de provincie en het taalgebruik in contact met bestuursorganen. In mijn onderzoek naar digitalisering en tweetalig bestuur in Fryslân uit 2025 kwam ik steeds hetzelfde paradoxale beeld tegen: de Friese taal is relatief sterk aanwezig in mondelinge interactie met burgers via loket en telefoon, maar veel zwakker in geschreven en digitale dienstverlening. Dat maakt het Fries tegelijk sterk (als levende bestuurstaal) én kwetsbaar (als digitale bestuurstaal).
Juist daar verschuift AI de grenzen. Vanaf 2016, met de brede introductie van neurale machinevertaling door Google, werd automatische vertaling in veel talen merkbaar beter door meer contextgevoeligheid op zinsniveau. Daarna volgden nieuwe sprongen: Meta zette met NLLB in op grootschalige vertaling van ‘low‑resource’ talen en maakte modellen publiek beschikbaar. En Microsoft zette neurale vertaalsystemen én maatwerk‑mogelijkheden (customisation) in de etalage, waardoor kleinere organisaties eigen taaldata beter kunnen benutten.
In mijn rapport over het Fries in de digitale overheid probeerde ik die technologische belofte niet als hype te behandelen, maar als bestuurlijke vraag: wanneer is het goed genoeg voor dienstverlening, en welke waarborgen (privacy, revisie, kwaliteitscontrole) horen daarbij?
Nedersaksisch: erkenning zonder uitvoeringsmotor
Het Nedersaksisch is in Nederland een grote taal in sociologische zin: het betreft een cluster van varianten in het noorden en oosten, met sterke lokale wortels. Beleidsmatig is het echter een kleine taal, omdat het onder het Handvest alleen onder Deel II valt. Dit betekent: erkenning van de culturele waarde van de minderheidstaal, maar zonder verplichtingen zoals bij Deel III. Wie op lokaal niveau meer zichtbaarheid en gebruik van de taal wil, moet dus zélf bestuurlijke instrumenten creëren.
In 2018 maakten het Rijk en vijf provincies (Groningen, Drenthe, Overijssel, Gelderland en Fryslân) daarom afspraken in een convenant, waarin samenwerking en beleidsondersteuning rond de regionale taal centraal staan. Het interessante aan zo’n convenant is dat het erkent dat Deel II zelden vanzelf leidt tot zichtbaarheid in onderwijs, media en bestuur: je hebt coördinatie, netwerkvorming, materiaalontwikkeling en politieke wil nodig.
Toch blijft de discussie terugkomen of Deel II niet te weinig is om een taal toekomstbestendig te maken. In een onderzoek dat ik redactioneel begeleidde, wordt scherp uitgelegd waarom het verschil tussen Deel II en Deel III in de praktijk zo groot is: Deel II formuleert beginselen en is vrijblijvend, terwijl Deel III dwingt tot keuzes en uitvoering in concrete domeinen, waardoor beleid meetbaar en herhaalbaar wordt.
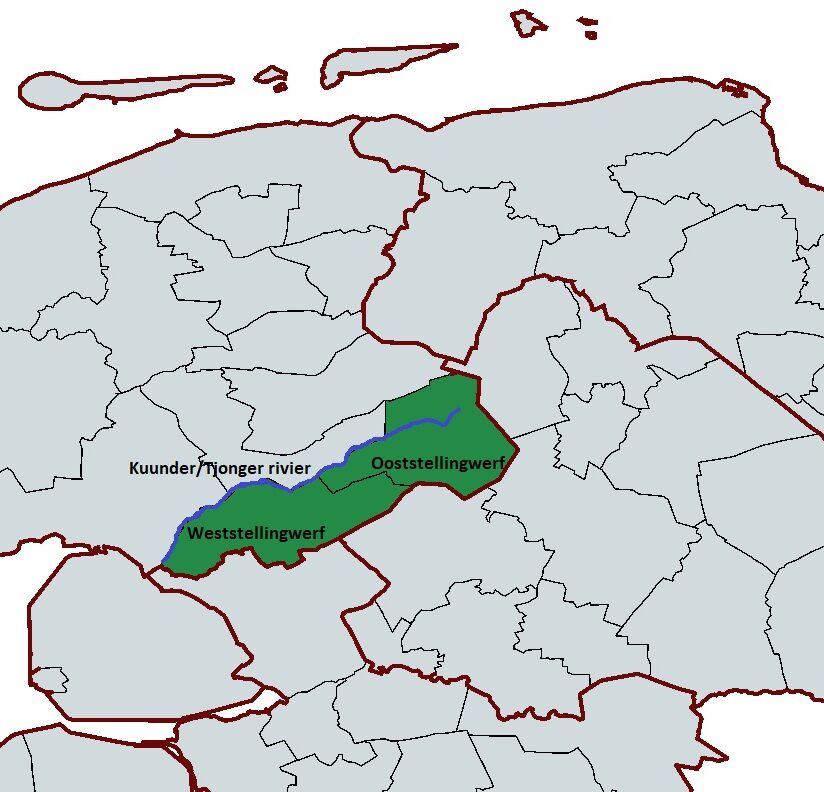
Het Stellingwerfs (in de Friese gemeenten Ooststellingwerf en Weststellingwerf) laat bovendien zien dat meertaligheid soms niet “twee talen in één gebied” is, maar een mozaïek: binnen een officieel tweetalig Fries‑Nederlands regime is een derde historische streektaal, het Stellingwerfs, de moedertaal. Dit soort situaties maakt het beleidsvraagstuk scherper: meertaligheid vraagt om maatwerk per subregio, niet om één uniforme taalregel voor een hele provincie of gemeente. Nu staat het Stellingwerfs, een variant van het Nedersaksisch, in deze gemeenten onder druk van zowel het Nederlands als het Fries die beiden een wettelijk sterkere positie hebben. Deze situatie gaat in tegen de geest van het Europees Handvest dat juist een omgeving wil creëren waarin minderheidstalen kunnen bloeien en groeien.
Limburgs: AI als versneller en als strijd om zeggenschap
Het Limburgs heeft sinds 1997 erkenning onder Deel II van het Handvest. Daarmee is het formeel een regionale taal binnen het Europese kader, maar in veel beleidsterreinen blijft het vooral een cultuurtaal: aanwezig in identiteit en informele communicatie, maar zeer beperkt geïntegreerd in onderwijs, dienstverlening en de digitale overheid.
In een onderzoek uit 2025 komt naar voren dat de technologische ontwikkelingen nieuwe kansen bieden, zelfs al heeft het Limburgs nog geen erkenning onder Deel III. Technologie verandert namelijk de kosten‑batenanalyse van taalbeleid. Waar “vertalen is te duur” jarenlang als stopargument dienst deed, wordt AI‑vertaling nu gezien als een levensvatbare route om dienstverlening in regionale talen betaalbaar en schaalbaar te maken—zeker voor digitale kanalen waar veel communicatie gestandaardiseerd is, zoals formulieren, sjablonen en webpagina’s. Dit is geen garantie voor succes, maar het verwijdert wel een klassieke politieke blokkade.
Maar AI versnelt niet alleen, het herverdeelt ook macht. Zo zette in juni 2024 Google de grootste uitbreiding van zijn programma Translate ooit door, met 110 nieuwe talen, waaronder het Limburgs. Het Limburgs is echter (nog) geen gestandaardiseerde taal en Google heeft zodoende een mix gemaakt van Limburgse dialecten om zo tot een Limburgse ‘taal’ te komen. Dit roept de vraag op: wie bepaalt wélke variant en wélke norm digitaal “het Limburgs” wordt? Dit is geen onbeduidend argument want zodra een platform één vorm bevoordeelt, krijgt die vorm status, vindbaarheid en (op termijn) bestuurlijke bruikbaarheid. In een kleine taal kan een digitale norm, spelling, terminologie, “wat is correct”, de toekomst van de taal vormgeven. De vraag “wie beslist?” is daarmee onvermijdelijk: Big Tech, een commissie, de gemeente, de taalgemeenschap, of een combinatie?
AI-vertaling en digitale soevereiniteit: van toegang tot zeggenschap
Moderne vertaalmachines werken niet meer met woordenlijsten en grammaticale regels, maar met neurale netwerken die patronen leren uit enorme hoeveelheden voorbeeldzinnen. Die voorbeeldzinnen zijn doorgaans ‘parallelle corpora’: dezelfde tekst in twee talen, zin voor zin uitgelijnd.
Hoe meer consistente data beschikbaar is, hoe beter het model leert. Voor kleine talen is dit een structureel probleem omdat er vaak weinig grote, goed uitgelijnde corpora beschikbaar zijn. Ze worden daarom aangeduid als low-resource languages. Recente onderzoeken laten echter zien dat AI-modellen het Fries, Nedersaksisch en Limburgs al voldoende beheersen om bruikbare vertalingen te leveren. Desalniettemin werken taalonderzoekers voortdurend aan verbetering van de AI-modellen door ze nieuwe trainingsdata te leveren. Hier raakt taalbeleid aan een bredere kwestie: digitale soevereiniteit.
Digitale soevereiniteit betekent niet technologische autarkie, maar zeggenschap over digitale representatie. Wie beheert de datasets? Wie kan correcties aanbrengen? Wie bepaalt de terminologie? Wie profiteert van de waarde van taaldata?
In eerdere projecten rond het Noord- en Saterfries (Friese minderheidstalen in Duitsland) werd mij duidelijk hoe hoog de toegangsdrempel kan zijn. Grote technologiebedrijven vroegen aanvankelijk omvangrijke parallelle corpora (een miljoen zinnen), consistente spelling en langdurige community-validatie. Voor kleine talen met beperkte institutionele middelen is dat een vrijwel onmogelijke opgave. Big Tech fungeert daarmee behalve als promotor ook als poortwachter van digitale beschikbaarheid. Niet zozeer vanuit ideologische afwijzing, maar veeleer uit schaal- en efficiëntielogica. Talen met weinig data leveren weinig directe economische waarde op. Voor Nederland rijst daarom een fundamentele vraag: willen we dat regionale talen digitaal bestaan bij de gratie van internationale platformbeslissingen, of bouwen we eigen infrastructuur – open corpora, terminologiebanken, fine-tuned modellen – waarop publieke instellingen kunnen voortbouwen? Digitale soevereiniteit betekent dat taalbeleid óók data- en innovatiebeleid wordt.
In de twintigste eeuw draaide minderheidstalenbeleid om scholen, omroepen en rechtszalen. In de eenentwintigste eeuw gaat het ook om datasets en cloudservers. Een taal die niet voorkomt in zoekmachines, vertaalmachines en administratieve software verliest geleidelijk publieke functionaliteit. Digitale afwezigheid wordt zodoende maatschappelijke afwezigheid. Dit betekent niet dat klassieke rechten irrelevant zijn. Integendeel: zonder juridische basis ontbreekt de legitimiteit. Maar rechten zonder digitale implementatie worden symbolisch. Digitale implementatie zonder democratische zeggenschap wordt technocratisch. De uitdaging is om beide te verbinden.
Naar een nieuwe beleidsagenda
Wat betekent dit concreet voor het Fries, Nedersaksisch en Limburgs?
- Investeer in open, publiek toegankelijke taalcorpora.
Overheden genereren dagelijks tweetalige documenten. Maak die systematisch beschikbaar als trainingsdata. - Ontwikkel terminologiebanken voor bestuur en recht.
Bestuurlijke bruikbaarheid vereist consistente terminologie. - Stimuleer fine-tuning in plaats van volledige afhankelijkheid.
Combineer bestaande modellen met lokale data en controle. - Veranker human-in-the-loop-kwaliteitscontrole.
Technologie versnelt, maar menselijke expertise borgt de betrouwbaarheid. - Organiseer democratische zeggenschap over digitale normen.
De vraag “wie beslist?” mag niet toevallig (on)beantwoord worden.
Conclusie: van erkenning naar bestuurbaarheid
Minderheidstalen overleven niet alleen door liefde of juridische erkenning, maar door infrastructuur. Infrastructuur was ooit een schoolgebouw; nu is het ook een dataset. De kernvraag verschuift daarbij van “is de taal erkend?” naar “is de taal digitaal beschikbaar?”. Kan zij functioneren in de digitale overheid, in onderwijsplatforms, in administratieve systemen? Is haar digitale norm legitiem en controleerbaar? Taalrechten zonder digitale infrastructuur blijven fragiel. Digitale infrastructuur zonder democratische zeggenschap wordt willekeurig. De toekomst van minderheidstalen ligt daarom niet alleen in verdragen en wetten, maar ook in de organisatie van hun digitale bestaan. Wie die organisatie uitbesteedt zonder regie, besteedt haar culturele toekomst uit. Wie haar bewust vormgeeft, maakt van taal geen reliek van het verleden, maar een volwaardige speler in het publieke domein van morgen.